

Top Book Recommendation Systems to Discover Your Next Read
A ML project on book recommendation system


Introduction
Have you ever wondered how Amazon manages to recommend suitable books to loads and loads of its different user bases? In this blog, I’ll walk you through how I built the book recommendation system using ML and deployed it.
Problem Statement: Searching best book to read by own is hectic. Why not build a personalized book recommendation system that would find perfect book for one or a bunch of very popular books that many had read?
Objective: To build a flexible book recommendation system that recommends books based on user preferences and popular trends.
Overview of the Project
What does the system do? The system recommends books to users based on their reading history, based on other similar users reads, and popular books in the dataset.
Key Features:
Popularity-Based Recommendations: Suggests the top 50 popular books.
Content-Based Filtering: Recommends books similar to the given book a user had read before.
Collaborative Filtering: Recommends books based on users ratings and preferences.
Deployment: The whole system is deployed as an web app in Heroku and is accessible to all.
Data Collection and Preprocessing
Dataset: The dataset I used in this project is Book Recommendation Dataset. It is free to use.
Dataset Description: There were three csv files.
Books.csv

Ratings.csv

Users.csv

Preprocessing Steps
Handling Missing Values:
Filtering out books with fewer than 50 ratings to ensure quality recommendations.
Creating pivot tables for collaborative filtering.
Using TF-IDF for content-based filtering.
Modeling and Algorithms
Popularity-based Filtering: It is a kind of filtering which focuses on finding the most popular contents in the entire dataset and present it to all the users. For eg. top 200 IMDB rating movies of all time.
Here, I had done the top 50 most popular books (minimum 250 ratings) based on average rating by the users. Step by step:
Find out the number of ratings for each books:

Find out average rating for those books.

Filtering out the books with ratings more than 250 and sorting in descending with respect to average rating

Saving the recommendations in pickle file for application development.

- Content-based Filtering: It is a kind of filtering where user past preferences are taken into account and items with attributes similar to those past preferences’ attributes are recommended to the users.
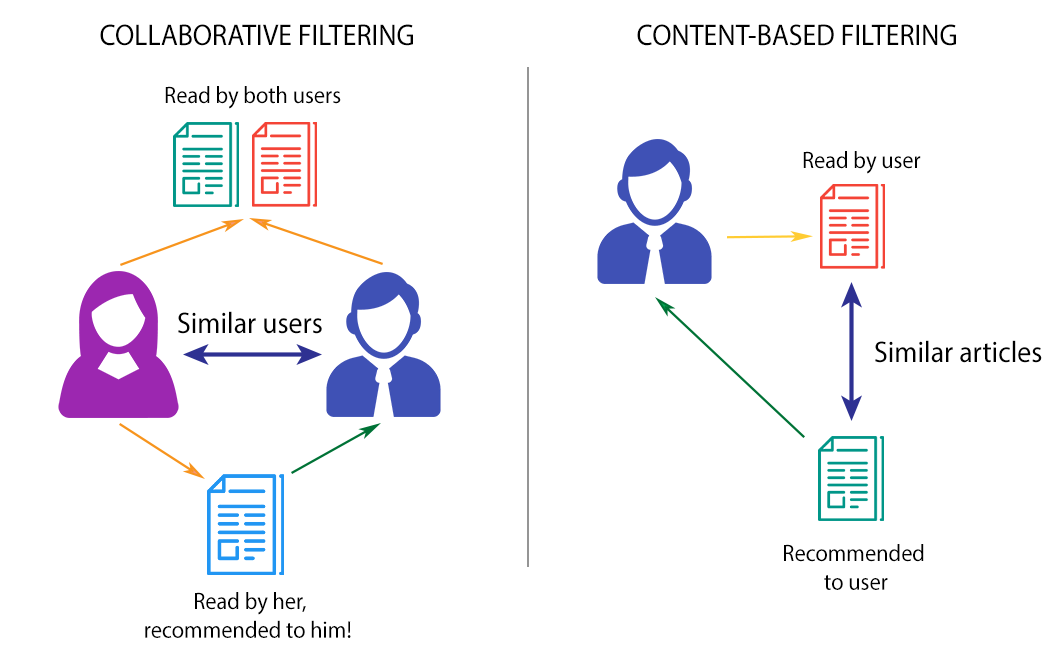
Create user profiles based on author, publication and year books they read.

In ‘user_id’ column, there are the users who has rated more than or equal to 4 books. In each row, there are all the authors, publishers and years books a specific user read.
Create a new column ‘content‘ where author, publisher and year is combined for each book and fill the null contents (for vectorizing).

Use TfidfVectorizer to convert textual features into numerical features

How TfidfVectorizer works?

Fig: TfidfVectorizer (source: KDnuggets)
Why TfidfVectorizer used for content-based filtering?
First, ML algorithms works on numerical data so it is necessary to convert text data into numerical representations.
Second, it helps measure similarity between user profiles and content (books) that helps in personalized recommendations.
I transformed books_data[‘content’] into numerical matrix using TfidfVectorizer. This means
Each row represents a unique book in the dataset.
The column represents the unique terms extracted from the content column from each book.
Each cell contains the TF-IDF score of a term in a specific book. This score reflects the term's relevance in the book compared to its occurrence across all books in the dataset.
- Then, cosine similarity is calculated between all the contents and content similar to users’ past preferences are recommended to those users.


- Finally, saving all the necessities for the application development.

Collaborative Filtering: It is a kind of filtering in which ratings matter the most. This filtering widely depends on the ratings provided by other users to recommend a product or content to one user.
There are two types of collaborative filtering: They are:
User-user based collaborative filtering:
Item-item based collaborative filtering:Selecting only users who have done more than 200 ratings: To ensure correct recommendation, we need enough data for each user. So, filtering out the user with less amount of rating data.


We have 899 users with ratings more than 200.
Getting ids of all the users in the list.

Merge ratings data and books data on ‘ISBN’ column

Create a final ratings dataframe with number of ‘ratings per book’ column

Select only the books with more than or equal to 50 ratings

Drop the duplicates and save it in final ratings dataframe once again

Create a pivot table

What is a pivot table?
A pivot table is a structured format that organizes data into matrix.
Here in the project, rows represent the books title whereas columns represent the user ids.
The values are the ratings given by users to each books.
Why is pivot table needed for collaborative filtering?
We have to use some ML algorithms to calculate similarities between different users and their preferences. For this, we use k-Nearest Neighbors (KNN) algorithm (matrix factorization can also be used). This algorithm needs structured format to get the job done. Thus, pivot table (book_pivot, in the project) is here for the rescue.
Also, missing values represent no interaction between user and book which further simplifies the process of finding patterns. Thus, user-item matrix simplifies operations like cosine similarity between users or items.
I think you understand now why pivot table is created.
Fill the null values with 0s.

Create a compressed sparse row matrix.

What is sparse matrix?
It is a matrix in which most of the elements are 0s.What is the issue with pivot table?
Pivot table are very sparse. Users often interacts with only some of the books even when thousands of books may present. Storing book_pivot as dense matrix leads to storing of large numbers 0s wastes the memory and is computationally expensive.What is the solution?
A CSR matrix efficiently represents sparse matrices by storing only non-zero values and their indices which reduces memory uses and improve computational speed.Here in the figure below, ind_ptr stores the cumulative sum of the non-zero values traversing row by row, indices gives the position of data in the row and data is the actual value present.
For example: Traversing from left to right in first row, total non-zeros is 2, so ind_ptr increases from 0 to 2, two non-zeros in second row, so 2 → 4, one non-zeros in third row, so 4 → 5 and finally for two non-zeros in 4th row, 5 → 7. Again, indices show value at 0 and 2 positions of 1st row. Finally, data show 3 and 2 as the actual values.
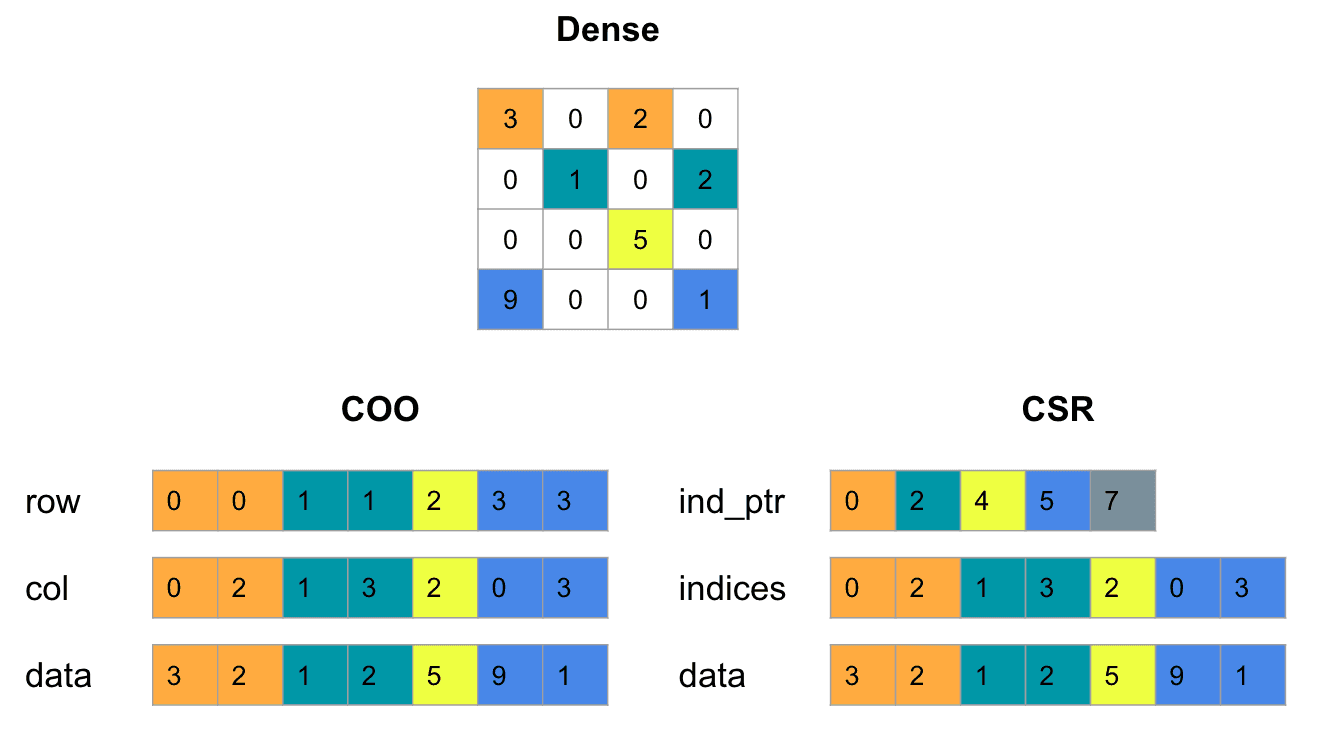
Fig: CSR Matrix (source: Hippocampus’ Garden)Finally the CSR matrix is fit to k-NN model.

Testing for an index

Saving the model and other dataframes

Testing the recommendation


With this, we completed three flavors of book recommendation system.
Deployment in Render
I used Render to deploy my streamlit webapp because it is easy and simple.
Future Improvements
Hybrid models: Both content based and collaborative filtering can be combined to get even more effective recommender system.
User Feedback: Looking forward to incorporate users feedback to improve recommendations.
Scalability: Making recommendation system on dynamic dataset with highly scalable system design.
Conclusion
In this way, we can build a recommender system for not only books but also different other applications. I learned a lot about handling big datasets, specific ML models and mathematics used in recommender systems and how to deploy the ML applications. I highly encourage you to build the app yourself and try out the app in the link below in the Code and Resources section.
Code and Resources
Here are the links to code and resources used:
Dataset Link: https://www.kaggle.com/datasets/arashnic/book-recommendation-dataset
Live App: https://bookrecommendationsystem-a273.onrender.com/
GitHub Repo: https://github.com/Sudhin-star1/BookRecommendationSystem